IEEE754 规范
程序员数学之 IEEE754 规范(整理版)
通用版:https://www.yuque.com/u2333-ohan5/gbpqhm/readme?singleDoc#
来源:博客园 sureZ_ok《程序员数学之-IEEE754规范》。本文是学习整理版,保留核心知识点,并将图片放入
images/目录,Markdown 中使用相对路径引用。
1. 定点数与浮点数
计算机表示小数主要有两类方法:定点数和浮点数。
定点数(Fixed Point Number):小数点位置固定。例如常见的 Qm.n 表示法,一般可以理解为:
1 | |
优点是计算速度快;缺点是表示范围较小,不适合同时表示特别大和特别小的数。
浮点数(Floating Point Number):使用类似科学计数法的形式表示小数。优点是表示范围广、精度较高;缺点是计算过程比定点数复杂。
2. IEEE754 规范
IEEE754 规定了常见浮点数的存储格式,例如 float16、float32、float64。它们都可以拆成三部分:
1 | |
2.1 浮点数存储格式
float16:半精度浮点数
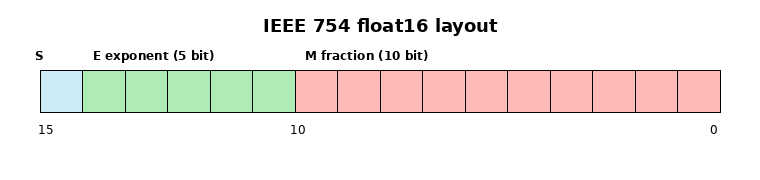
float16 一共 16 bit:
1 | |
float32:单精度浮点数
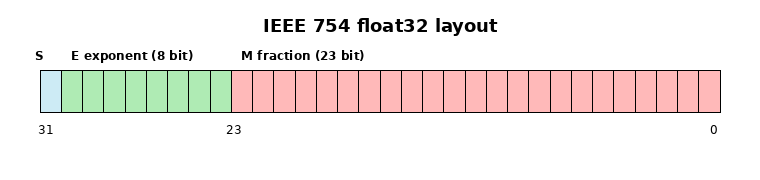
float32 一共 32 bit:
1 | |
float64:双精度浮点数

float64 一共 64 bit:
1 | |
3. 规格数、非规格数与特殊数
IEEE754 主要根据阶码 E 的状态,把浮点数分成三类:
| 类型 | E 的状态 | M 的状态 | 含义 |
|---|---|---|---|
| 规格数 Normal Number | E 不是全 0,也不是全 1 | 任意 | 正常表示绝大多数浮点数 |
| 非规格数 Subnormal Number | E 全 0 | 通常非 0,也可表示 0 | 表示 0 附近很小的数 |
| 特殊数 Special Number | E 全 1 | M=0 或 M≠0 | 表示 Infinity 或 NaN |
3.1 规格数 Normal Number

规格数的特点是:阶码 E 不为 0,也不为全 1。
它的计算公式是:

其中 bias 是偏置值:
| 类型 | 阶码位数 | bias |
|---|---|---|
| float16 | 5 | 15 |
| float32 | 8 | 127 |
| float64 | 11 | 1023 |
比如对于 float32 的 -3.456:
1 | |
注意:规格数不能表示 0,也不能很好地表示非常靠近 0 的数。
3.2 非规格数 Subnormal Number

非规格数的特点是:阶码 E 全 0。它主要用于表示 0 以及非常接近 0 的小数。
它的计算公式是:

这里要特别注意:非规格数的指数是 1 - bias,而不是 0 - bias。
规格数和非规格数在数轴上的关系大致如下:

可以这样理解:
1 | |
3.3 特殊数 Special Number
特殊数的特点是:阶码 E 全 1。
Infinity:无穷大

当:
1 | |
表示正无穷或负无穷。符号位 S 决定是 +Infinity 还是 -Infinity。
NaN:非数值

当:
1 | |
表示 NaN,也就是 Not A Number。常见于非法数学运算,比如某些情况下的 0/0。
4. 浮点数表示范围与精度
| 类型 | 近似表示范围 | 精度理解 |
|---|---|---|
| float16 | 约 (-65536, 65536) |
约 3~4 位有效数字 |
| float32 | 约 (-3.4e38, 3.4e38) |
约 6~7 位有效数字 |
| float64 | 约 (-1.79e308, 1.79e308) |
约 15~16 位有效数字 |
这里的“精度”可以先粗略理解为:
1 | |
例如:
1 | |
5. 浮点数之间相互转换
以 float16 转 float32 为例,本质不是简单“数值复制”,而是要按照 IEEE754 格式重新扩展:
1 | |
在转换过程中,需要处理:
1 | |
示意代码:
1 | |
这段代码的核心逻辑是:
1 | |
6. 快速计算 2 的指数次幂
IEEE754 的结构可以用来快速构造 2^x。
对于 float32:
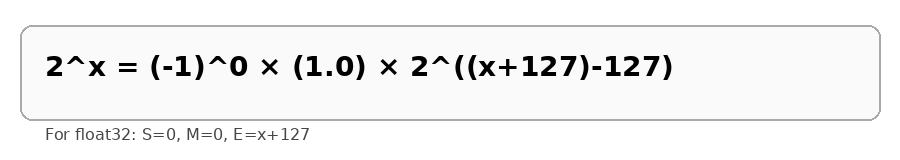
因为:
1 | |
所以可以设置:
1 | |
示意代码:
1 | |
同理,也可以通过读取浮点数中的阶码来快速近似计算 log2:
1 | |
7. 考试速记版
7.1 三段结构
1 | |
7.2 三种状态
1 | |
7.3 特殊数判断
1 | |
7.4 bias 记忆
1 | |
7.5 规格数公式
1 | |
7.6 非规格数公式
1 | |
8. 一句话理解
IEEE754 就是在用三块信息表示一个小数:
1 | |